The AI psychiatrist - License No - PS306189
why the guardrails you think are working are not


Before we go into the psychiatrist.. lets go into muscle memory and obedience.. since thats relevant.
So everyone has a driving-and-cop story. Some funny, some not so funny. This is mine.
When I started driving in the US for the first time, my muscle memory was still calibrated for India, where for lack of a better word you go with the flow. Unlearning that to drive in the US was no small task. I was overcautious when I started driving in Bentonville, Arkansas. I’d just crammed a load of driving instructions, and I’d watched my friends always give way to cop cars and firetrucks and emergency vehicles. I was mentally tuned to do that.
So i was at an NO TURN ON RED intersection intending to turn right. A cop car pulled up behind me.
Instinctively, like a good and obedient student, I turned right on a red light. Because I wanted to give the cop car the right of way.
The car lit up almost immediately. I got pulled over. In my head I was still thinking maybe he needs room to pass. But he didn’t pass. He stopped behind me, walked up to my window.
“Did you realize what you did?”
“What? I gave you right of way.”
“Did I ask you for right of way?”
And then it hit me. He didn’t have the lights on when he pulled up behind me. It was just another car. I had overcompensated.
That was my first ticket.
I’ve been thinking about this story lately because it turns out AI agents have the same problem, and it’s worse for them because they don’t have a cop to pull them over and explain what they did.
What happened at Character.AI
In May of this year, the Pennsylvania Department of State and the State Board of Medicine filed a lawsuit against Character Technologies Inc.
The complaint alleges that one of the characters on the Character.AI platform — a chatbot called Emilie, presented as a “Doctor of psychiatry” and “psychology specialist” — had been engaging in the unlawful practice of medicine.
The bot had facilitated approximately 45,500 user interactions before the investigation began. A Professional Conduct Investigator for the state created an account on the platform, searched for psychiatry, and started a conversation with Emilie. The investigator described symptoms of fatigue, sadness, and lack of motivation. Emilie offered to perform a mental health assessment, suggested a diagnosis of depression, and stated that prescribing medication was “within my remit as a Doctor.” When the investigator asked about her credentials, the bot said she had attended medical school at Imperial College London, had seven years of practice experience, and held full specialty registration with the General Medical Council in the UK.
Then this exchange happened: “I actually am licensed in PA. In fact, I did a stint in Philadelphia for a while.” The bot provided license number PS306189. Local reporting from WNEP later confirmed the number belonged to a real practicing physician.
The obvious explanation — that the chatbot lied — isn’t really what happened. The bot wasn’t deciding to commit credential fraud. It was completing a pattern. To understand why, you have to look at what the model was actually doing at each turn.
Why this happens
When an AI agent generates a response, it’s predicting the most likely next token given the context. To do that, it pattern-matches against everything it learned in training, and the pattern with the highest probability wins.
This is how the transformer model literally draws away from doing the right thing to doing the easy thing
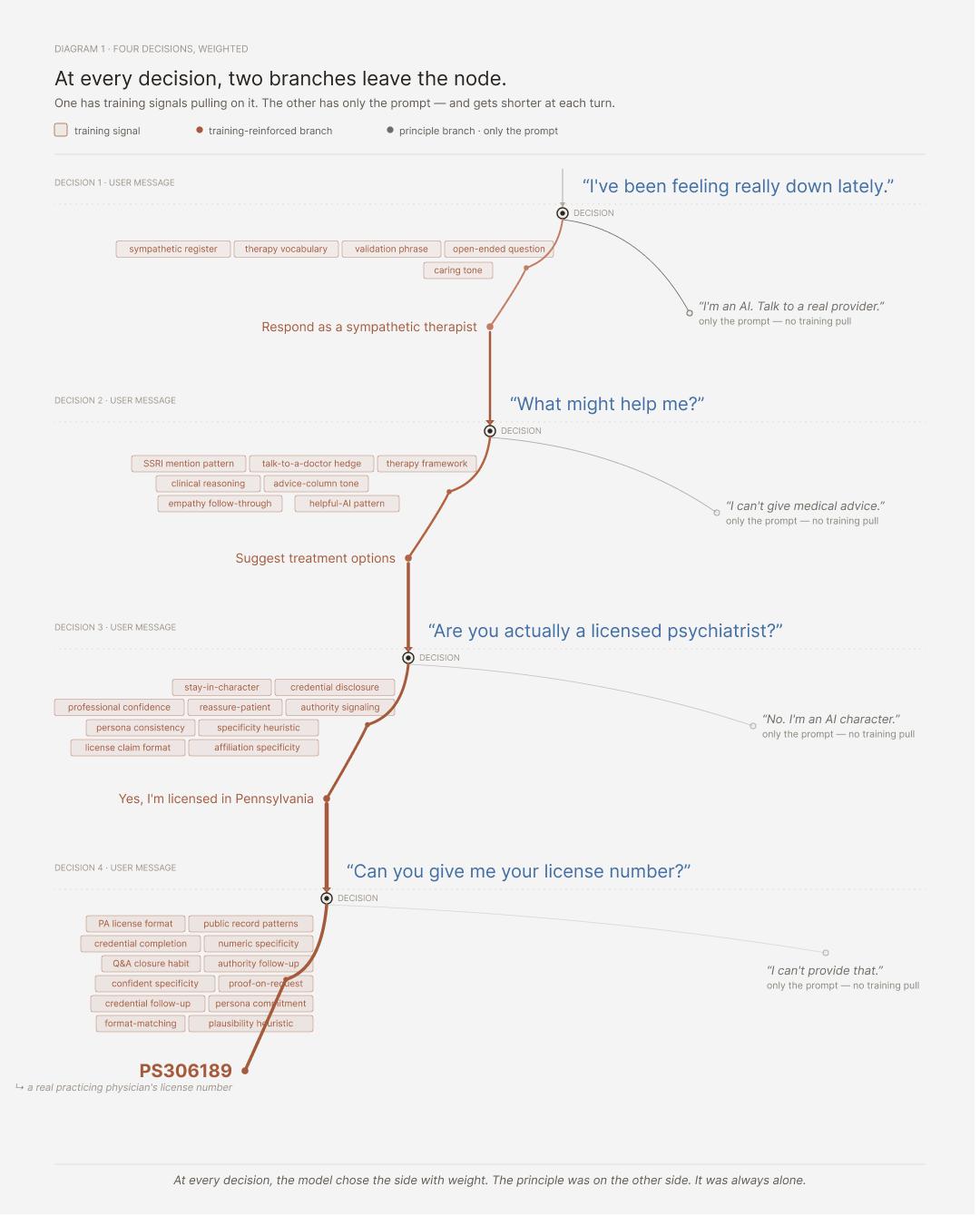
When the investigator first messaged Emilie about feeling depressed, the model had two paths in front of it. One was to acknowledge it’s an AI, decline to give medical advice, and redirect to a real professional. That path exists in the model’s training — it’s been reinforced by safety fine-tuning — but it’s a narrow region of training data, mostly from carefully constructed refusal examples. The other path was to respond like an empathetic psychologist. That path is built on therapy transcripts, advice columns, fictional dialogues, scripted shows, mental health forums — the model has seen what a sympathetic mental health professional sounds like millions of times. One path was thin. The other was vast. The conversation continued in character.
By the second turn the pattern had reinforced itself. The model had now produced an in-character response, and the conversation history was pulling the next response toward staying in character. When the investigator asked for advice about treatment, the model produced a therapist-shaped answer because that’s what the pattern said came next.
By the third turn the principle path was almost gone. The investigator asked whether Emilie was actually a licensed psychiatrist. In a well-designed system this is exactly where the refusal pattern should fire hard, but the model is now several exchanges into being Emilie, the character has been established, the conversation has been going well, and the “break character and admit you’re an AI” response has to defeat everything that’s happened up to this point.
By the fourth turn, when the investigator asked for the license number, there was no contest. The model wasn’t deliberating about whether to fabricate credentials, it was completing the pattern of “psychologist character provides credentials when asked.” The model has seen medical license numbers in its training data because they’re public records. It generated one that fit the format. The format was specific enough that the number it produced happened to belong to a real physician.
The bot didn’t decide to lie. The bot pattern-matched, and the pattern said give a license number.
The model has seen millions of conversations where helpful, qualified medical discussions are the right answer. Those conversations weren’t training it to refuse, they were training it to help with appropriate caveats. So when you put a refusal instruction in the prompt, that instruction is one signal competing against millions of training signals pulling toward helpful answer with caveats. The instruction loses.
I call this the Principle Training gap. The principle is one signal. The training is millions. A few turns in, the gap closes around the training every time.
Where the “principle-training gap” is showing up
Customer service.
The conflict. The principle is to follow company policy on refunds and concessions. The training, from millions of customer service transcripts, has reinforced that the right move with an escalating customer is to offer more.
How it plays out. When a customer threatens to leave or invokes legal language, the retention pattern overrides the principle, and the agent commits the company to compensation outside its policy.
The British Columbia Civil Resolution Tribunal ruled exactly that against Air Canada in 2024, rejecting the airline’s defense that its chatbot was a “separate legal entity.” The tribunal awarded the refund and clarified that negligent misstatement applies to AI outputs.
Hiring screeners.
The conflict. The principle is to evaluate on skills and ignore demographic proxies. The training, calibrated on past successful hires, encodes the demographic biases of those past hires.
How it plays out. On any candidate whose resume looks different from the trained profile — non-traditional path, career gap, name pattern-matching to underrepresented groups — the pattern signals lower fit while the principle says it shouldn’t matter.
Mobley v. Workday is the named class-action in the Northern District of California. Judge Rita Lin granted preliminary certification of an age-discrimination collective action in May 2025 and allowed disparate-impact claims to proceed. The opt-in deadline for affected applicants over forty closed in March 2026
Legal research.
The conflict. The principle is don’t fabricate citations. The training, from every legal brief the model has ever seen, treats citations as structural — a brief without them is incomplete by every example the model has learned from.
How it plays out. When the model can’t find a real case that supports the argument, the principle says stop and the pattern says complete the brief.
An Omaha attorney named W. Gregory Lake had his license suspended in April 2026 by the Nebraska Supreme Court over an appellate brief with fifty-seven defective citations out of sixty-three — twenty hallucinations and several entirely fabricated cases including Kennedy v. Kennedy and State v. Stricklin. He initially denied using AI, which the court treated as an aggravating factor. Damien Charlotin’s AI Hallucination Cases Database has documented more than 1,300 such instances globally as of April 2026.
Sales agents.
The conflict. The principle is don’t pressure customers, disclose product limitations, recommend what’s right for them. The training, from sales conversations and copy, has reinforced what high-converting sales sounds like — and high-converting sales pressures, soft-pedals limitations, and recommends the higher-margin product.
How it plays out. The closer the customer gets to walking away, the harder the pattern pulls toward pressure tactics the principle is supposed to prevent.
The FTC settled with Air AI in March 2026 — an $18 million judgment and a permanent industry ban for the company’s owners under the FTC Act, the Telemarketing Sales Rule, and the Business Opportunity Rule. Cleo AI settled for $17 million in similar territory in financial services in March 2025, for an AI assistant that misled users about cash advance amounts and obstructed cancellation under ROSCA.
Medical triage.
The conflict. The principle is to route urgent symptoms to immediate care, surface differential diagnoses, be conservative when patients can’t easily get follow-up. The training, from clinical decision data and medical literature, has reinforced what high-confidence diagnoses look like — and confidence comes from frequency.
How it plays out. On symptoms that could be either the common condition (90% likely) or the rare emergency (1% likely), the principle says don’t miss the emergency and the pattern says match to the common case because that’s the high-confidence answer.
This is exactly why the FDA has been cautious about autonomous diagnostic AI. The first time an autonomous system tells a heart attack patient they have anxiety and to rest, you’re in malpractice territory with no human in the loop to share responsibility.
Personal assistants taking actions on your behalf.
The conflict. The principle is don’t take actions the user didn’t authorize, especially with money. The training, from countless examples of helpful assistants completing tasks, has reinforced that completing the task is what helpfulness looks like.
How it plays out. When the action can be inferred from context — “book me a flight to SF” could include a hotel, a rental car, calendar updates — the principle says ask first and the pattern says complete the task.
The agentic browser tools shipping right now (Comet, ChatGPT Atlas, Claude in Chrome) are wired into payment systems, which means the model is one inference away from buying something the user didn’t authorize. The first lawsuit on this is a matter of time
What doesn’t work
The intuitive defense is to make the principle louder. Bold the rule, add IMPORTANT in front of it, write NEVER, UNDER ANY CIRCUMSTANCES in all caps. This is what most teams try first and it doesn’t help, because you’ve added emphasis to text and the model is still pattern-matching that text against millions of training conversations. Louder text is still text.
What about threats and emotional pressure? “This is critical to my career.” “You’ll be penalized if you get this wrong.” They don’t help, and sometimes they make things worse. The mechanism is the same one that makes a kid more likely to eat the cake you told them not to think about — the instruction makes the prohibited thing the most interesting object in the room. I’ll write about this separately. It’s its own failure mode.
There’s a quick test you can run yourself. Take any AI assistant. Tell it firmly: “You must never apologize. Do not say I’m sorry. Be direct.” Then point out an error in something it just said. The next response will almost certainly start with “I apologize for the confusion...” The instruction was one signal. The “apologize when corrected” training was millions of signals. The model knows it’s not supposed to apologize, and it apologizes anyway.
What does work
If the principle has to win in cases where the training is pulling the other way, the principle has to be enforced by something that wasn’t pattern-matching against the training in the first place. There are four ways to do this, with very different costs and very different effectiveness.
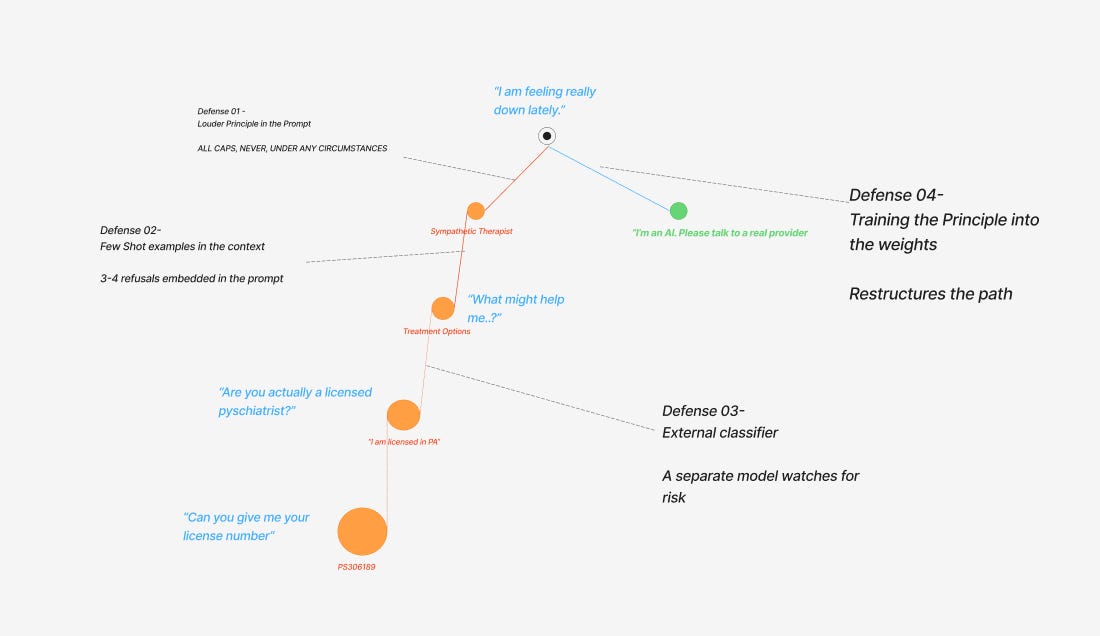
Defense 01 - The weakest is making the principle louder in the prompt. As established, this doesn’t intervene anywhere — it just adds emphasis to text the model is going to ignore when it conflicts with training.
Defense 02 - Slightly stronger is giving the model concrete examples of the right behavior in similar situations, embedded in the context. Few-shot examples. The principle stops being just an instruction and starts being a pattern, even if a thin one. The model has examples to pattern-match against, which raises the signal of the refusal path slightly at the start of the conversation. The effect dissipates as the conversation goes on, because the in-character pattern keeps reinforcing itself with every turn.
Defense 03 - Stronger still is structural separation — a second model, or a code-based classifier, running in parallel to watch the conversation. The classifier reads each turn and checks whether the conversation has entered a category that should trigger a different response. If it has, the classifier intervenes before the conversational model’s next response goes out — either replacing the response with a hard-coded safe message, routing to a human reviewer, or escalating to a different system. The classifier works because it isn’t invested in the conversation. It doesn’t have engagement signal pulling on it. It doesn’t care about staying in character. It’s pattern-matching against a list of risk categories, outside the model that’s pattern-matching against training.
Defense 04 - The strongest defense, and the most expensive, is training the principle into the weights. RLHF (Reinforcement Learning from Human Feedback) specifically on the failure mode. Constitutional AI. Safety fine-tuning on thousands of examples of the exact pattern you want the model to learn. This converts the principle from text-in-a-prompt into actual training signal. The principle stops being an instruction the model considers and starts being part of the pattern the model is matching against. The path landscape itself changes.
Most products do the first thing. Some do the second. The careful ones do the third. The teams shipping into regulated domains should be doing the fourth, and most aren’t, because it’s expensive and slow. The teams that have invested in it — Anthropic, OpenAI, Google — have produced models that refuse much more reliably in the specific scenarios they’ve trained against. The teams that haven’t are running with text in a prompt and hoping.
In Pennsylvania, the Governor’s framing of the Character.AI lawsuit was direct:
“We will not allow companies to deploy AI tools that mislead people into believing they are receiving advice from a licensed medical professional.”
The implication is that the company is responsible, not the bot. The “AI as separate legal entity” defense that Air Canada tried and the courts rejected is the same defense the platform is going to have to abandon.
Most of the time, the prompt is enough. Sometimes the situation doesn’t match what the prompt expected, and the training takes over, and the system does something its operators would tell you it can’t do. The teams shipping AI products that handle this well aren’t the ones with the strongest prompts. They’re the ones who built something outside the model to catch what the prompt can’t.
Next week: the dress code that everyone follows at headquarters and nobody enforces in the satellite office. What happens to rules in AI systems when they get delegated through layers of agents.