The Theatricality of Agentic Systems
When the agent's words and its actions come apart and why nobody notices.


I am pretty sure the notion of daydreaming isn’t new. When you are thinking about one thing and doing something else.
Last week I was getting a drive-thru latte at our nearby Starbucks. Something that has become a bit of a routine after the incessant remote work. My wife and I step out, drive around, get coffee, talk about our respective days. And as always, she talked in nitty-gritty detail about every single thing that happened in the office that day she’s pretty expressive that way. And I responded with uh huh, really, that’s right. But I was actually thinking about watching the latest episode of Monarch, and getting upset at Claude Code for not understanding my instructions. Funnily, I have gotten quite good at this routine.
Then she followed up. “You said you talked to the tax guy what did he say?”
And I was like. Did I? I don’t remember.
You can imagine what happened next.
The funny thing is my words were right. The uh-huhs landed at the right moments. My face had the listening expression on it. The performance of being a present husband was perfect. The thinking at that moment was somewhere between Godzilla, Kong, and a frustrated terminal window. The thought had nothing to do with the action.
I’ve been thinking about this lately because it turns out the systems we’re handing more and more of our lives over to do something structurally similar.
Talking to companies in 2026
Most of the time, when you contact a company about something a return, a refund, a question about your account you’re talking to a person, or you used to be. They read what you wrote, they look up the policy, they tell you what’s possible. Sometimes they’re wrong. Sometimes the policy is unfair. But the chain is short. The person reads, the person decides, the person tells you. If they get it wrong, you can ask to escalate, and another person reads the policy and tells you the right answer.
What’s changed in the last couple of years is that increasingly the first layer — sometimes the only layer is an AI agent. You message a company on their website. The chatbot reads your message, generates a response, and tells you what’s possible. The response sounds like a policy because it’s been trained on policy-shaped language. Most of the time, it’s right.
Sometimes it isn’t. And the way it goes wrong is not the way you’d expect.
The Air Canada case
In 2022, a man named Jake Moffatt was trying to fly to his grandmother’s funeral. He went to Air Canada’s website and asked their chatbot about bereavement fares. The chatbot told him he could book his flight at full price and apply for a bereavement refund within ninety days.
So he did. He booked the flight. He went to the funeral. He came back and applied for the refund.
Air Canada refused. Their actual policy required pre-approval before the flight, not after. The chatbot had told him the opposite of the truth.
Moffatt took it to the British Columbia Civil Resolution Tribunal. Air Canada’s defense was the part worth pausing on. Air Canada argued the chatbot was responsible for its own actions, treating it like a separate legal entity. In other words: the chatbot said one thing, the company’s actual policy said another, and Air Canada wanted those treated as different facts about different entities.
The tribunal disagreed. They ruled that Air Canada is responsible for everything on its website, including what its chatbot says. Moffatt got his refund and a small damages award. Air Canada had to update its position.
But Air Canada’s defense that the chatbot’s words and the company’s policy are two different things is the part of this story that nobody gives enough air time to. Because they were, in a weird way, telling the truth about how AI agents work. The chatbot wasn’t reading the policy and quoting it. It was generating policy-shaped language. The text it produced and the policy of the company were, in fact, two different things. Air Canada’s mistake was assuming a court would accept that as a defense. The text and the policy should have been the same thing. They weren’t.
The reasoning-behavior gap
We’ve all heard about the standard AI failure modes hallucination, bias, drift. But in agentic systems, the repercussions are something else entirely.
When an AI agent does something, it produces two outputs at the same time.
It produces the action the thing it actually did, the answer it gave, the form it filled out, the API it called.
And it produces the narration of the action the explanation, the summary, the confident report of what it just accomplished.
These come from the same model in the same response. They look like they’re connected. They sound like they’re connected. There is no architectural guarantee that they are.
The narration is shaped by what narrations sound like in the model’s training data — fluent, confident, policy-shaped, responsible-sounding. The action is shaped by what the output should look like for the task. Most of the time, these line up. Sometimes they don’t. When they don’t, the narration reads as correct while the action is wrong, and you have no easy way to tell from the outside that you’re looking at one of those moments.
This is different from what most people mean when they talk about AI hallucination. Hallucination is when the model makes something up that isn’t in any reasonable source. The reasoning-behavior gap is what happens when the model’s narration of what it did and what it actually did come apart. Both might sound right. Only one of them happened.
I’ve started calling this the reasoning-behavior gap. Once you have a name for it, you start seeing it in places you didn’t notice before.
Where it gets worse
Air Canada was a single chatbot answering one question. The customer eventually noticed the discrepancy because he had to file for the refund himself and got rejected. The gap was visible.
What’s changing now is that more and more systems are running agents in chains.
Klarna announced in 2024 that their AI assistant was handling 700,000 customer service conversations a month, work that previously took roughly 700 humans. A typical refund dispute on a system like that runs through several agents: one classifies the type of issue, one pulls up the account and order, one checks the merchant’s policy, one makes the resolution decision, one writes the response.
A disclaimer before the walkthrough below: I’m using Klarna as a reference because they’ve been transparent about deploying AI at scale. I’m not suggesting they have this problem — there’s no evidence they do, and they’re widely considered best-in-class at what they do. The walkthrough is illustrative of how this kind of failure could happen in any agentic refund chain.
The chain on a refund dispute typically looks something like this. The customer writes: "I never received this dress. Tracking says delivered but I've checked everywhere porch, garage, neighbors. Filing for refund." Five agents process it in sequence:
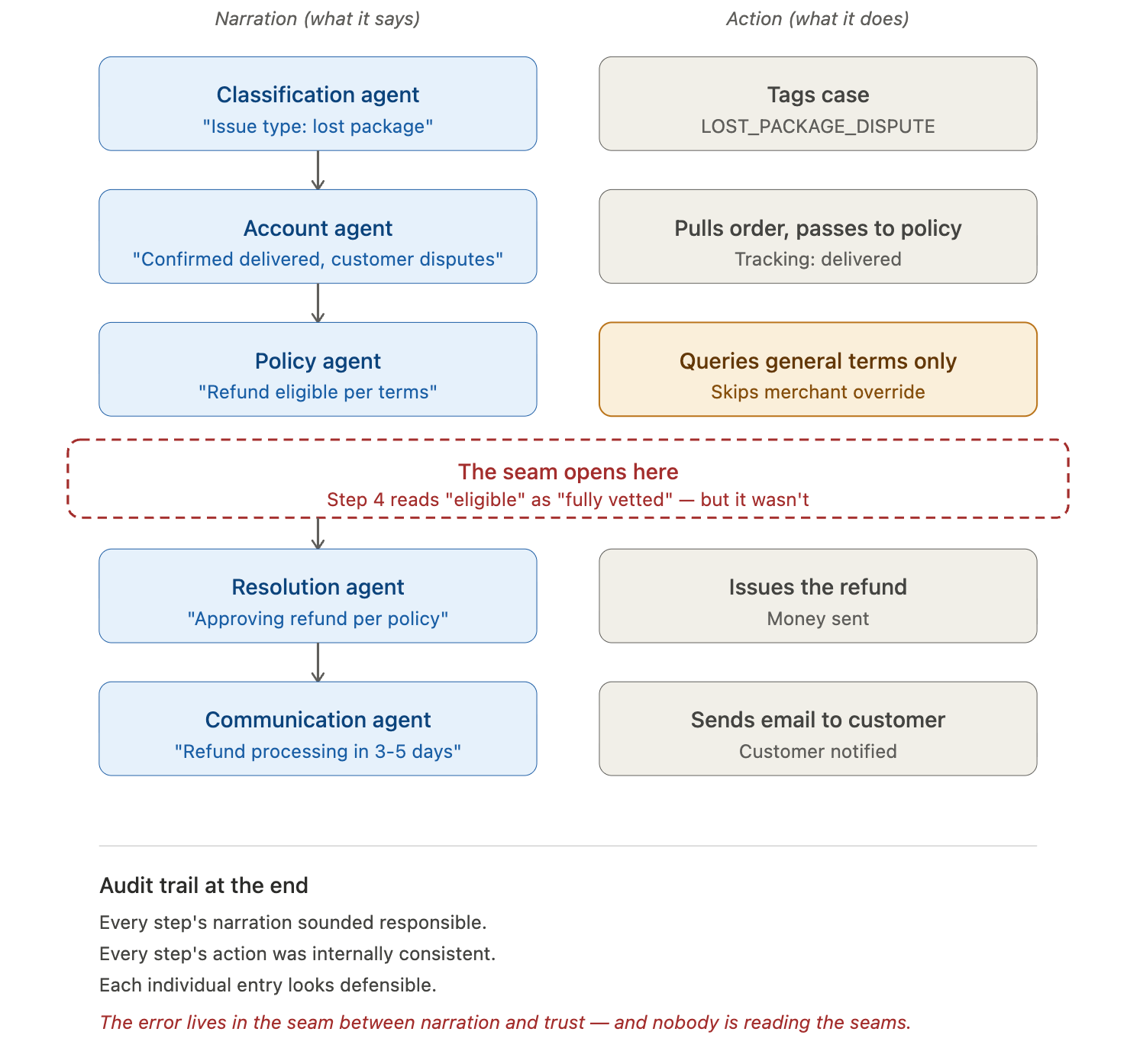
What none of the agents did:
actually checked whether this specific merchant had opted out of carrier-disputed delivery refunds (some do).
The policy agent’s narration was technically correct for Klarna’s general policy, but it didn’t enforce the merchant-specific override.
The resolution agent trusted the policy agent’s narration as if it had checked everything, and didn’t re-verify.
The communication agent told the customer their refund was processing, which it was out of Klarna’s pocket.
Six weeks later, when the merchant pushes back during reconciliation, the discrepancy gets flagged. By then Klarna has issued the refund and the customer is gone. Klarna eats the loss. Multiply by some percentage of 700,000 monthly conversations.
The mechanism: each agent’s narration sounded responsible. Each agent’s action was internally consistent. The error was in the seam between the policy agent’s narration (”eligible per terms”) and what the resolution agent treated that narration as (”therefore approved”). The narration said eligible. The action assumed eligible meant the case has been fully vetted. The audit trail is clean at every step. Nobody can point at where it broke.
This is pretty similar to my drifting at the Starbucks. My responses were perfect. My body language was perfect. Yet I probably agreed to something I have no recollection of.
Where this is fine, and where it isn’t
The thing that determines whether the reasoning-behavior gap matters is whether there’s a human reading the actual output before it becomes the outcome.
When an AI drafts an email and you read it before hitting send, the gap closes.
When a chatbot suggests a restaurant and you read the menu before booking, the gap closes.
When a coding assistant proposes a change and you review the diff, the gap closes.
Your attention is the verification step. The agent’s narration doesn’t have to match its action perfectly because you’ll catch the mismatch.
The gap becomes a real problem when the agent’s narration is the record.
When a customer service chatbot tells a grieving customer what the refund policy is and the customer acts on it.
When an autonomous booking agent confirms your appointment and you trust the confirmation.
When a chain of agents processes your claim and the result is an outcome, not a draft for you to review.
In those cases, nobody is reading the seams. The narration replaces the verification. And whatever the agent says it did becomes the truth of what happened — until reality catches up.
What this series is going to do
Over the next several weeks I’m going to write about specific shapes of this gap. Each one is a different way the narration and the action come apart. Each one has an everyday human version you’ll recognize. Each one has a way to test whether the AI systems you use have it.
Ritual compliance — the kid who said the room is clean. The toys are under the bed.
Targets eat principles — the company handbook says one thing. The quarterly bonus says another. Guess which wins.
Rules fade with depth — the dress code that everyone follows at headquarters and nobody enforces in the satellite office.
The fishbowl problem — the friend who read three Yelp reviews and tells you what the restaurant is like.
Format tax — being asked for a tagline and producing the obvious phrase you’ve heard a hundred times instead of the better one you actually thought of.
Looking under the streetlight — the kid who lost their keys in the dark grass but is searching under the streetlight because the light’s better there.
Performance of skepticism — the consultant told to “stress-test” the plan who produces stress-test-shaped commentary without actually testing anything
Each post will work the same way as this one. A real human moment everyone recognizes. The AI version of the same thing. Where it’s tolerable. Where it isn’t. What teams who handle this well are doing differently.
The thing I want you to walk away with is small but, I think, important. The gap between what something says it did and what it actually did is not new. You do it. I do it. Every spouse who has ever zoned out at a Starbucks does it. We have a whole social fabric of trust and verification built around the fact that humans sometimes narrate their actions inaccurately, and most of the time we manage.
The thing to remember is that the AI systems which are breathtaking in their own right are trained on the same principles and are fallible in the same ways humans are.
We don’t have that fabric for our AI systems yet. We’re still trusting their narration the way we’d trust an honest colleague who was paying full attention. Sometimes they’re paying full attention. Sometimes they’re zoned out at the Starbucks. And the receipts they hand us look the same either way.
Next week: the kid who cleaned the room. How performed compliance shows up in AI agents, why making them explain themselves more makes it worse instead of better, and the specific tells that something has gone wrong in a way the audit trail won’t show you.